预训练语言模型必读文献01-Semi-supervised Sequence Learning
摘要
我们提出了两种利用未标注数据来提高循环网络序列学习的方法。第一种方法是预测序列中的下一个元素,这是自然语言处理中的一个传统语言模型。第二种方法是使用序列自动编码器,该编码器将输入序列读入一个向量中,并再次预测输入序列。这两种算法可以作为后续监督序列学习算法的“预训练”步骤。换句话说,从无监督步骤中获得的参数可以用作其他监督训练模型的起点。在我们的实验中,我们发现,使用这两种方法进行预训练后的长短时记忆循环网络更加稳定,并且具有更好的泛化能力。通过预训练,我们能够训练长达数百个时间步长的长短时记忆循环网络,从而在许多文本分类任务中实现出色的性能,例如IMDB、DBpedia和20个新闻组分类任务。
1、简介
循环神经网络(RNNs)是建模序列数据的强大工具,然而,通过时间反向传播[36, 26]来训练它们可能很困难[8]。正因如此,尽管RNNs在表示序列结构方面很有用,但很少用于自然语言处理任务,如文本分类。
在许多文档分类任务中,我们发现通过仔细调整超参数,可以训练长短期记忆循环网络(LSTM RNNs)[9]以获得良好的性能。此外,一个简单的预训练步骤可以显著稳定LSTM的训练。例如,我们可以使用下一步预测模型,即自然语言处理中的循环语言模型,作为一种无监督方法。另一种方法是使用序列自动编码器,它使用一个RNN将长输入序列读入单个向量。然后,这个向量将被用来重建原始序列。从这两种预训练方法中获得的权重可以用作标准LSTM RNNs的初始化,以改进训练和泛化。
在我们的20个新闻组[16]和DBpedia[19]的文档分类实验,以及IMDB[21]和烂番茄[25]的情感分析中,通过循环语言模型或序列自动编码器进行预训练的LSTMs通常优于随机初始化的LSTMs。这种预训练帮助LSTMs在这些数据集上达到或超过之前的基线,而无需额外的数据。
我们实验的另一个重要结果是,在预训练中使用更多来自相关任务的无标签数据可以改善后续监督模型的泛化。例如,使用来自亚马逊评论的无标签数据来预训练序列自动编码器,可以将烂番茄的分类准确率从79.7%提高到83.3%,这相当于增加了大量标记数据的效果。这一证据支持了这样一个论点,即可以使用更多的无标签数据进行无监督学习来改善监督学习。通过序列自动编码器和外部无标签数据,LSTMs能够达到或超过先前报告的结果。
我们相信,与其他无监督序列学习方法(如段落向量[18])相比,我们的半监督方法(如[1]所述)具有一些优势,因为它可以方便地进行微调。我们的半监督学习方法与Skip-Thought向量[13]有关,但有两个区别。第一个区别是,Skip-Thought是一个更难的目标,因为它预测相邻的句子。第二个是,Skip-Thought是一种纯粹的无监督学习算法,没有微调。
2、序列自动编码器和循环语言模型
我们的序列自动编码方法受到了Sutskever等人[31]在序列到序列学习(也称为seq2seq)方面的工作的启发,该方法已成功应用于机器翻译[20, 10]、文本解析[32]、图像字幕[34]、视频分析[30]、语音识别[4, 3]和对话建模[27, 33]。他们方法的关键是使用一个循环网络作为编码器,将输入序列读入一个隐藏状态,该隐藏状态是解码器循环网络的输入,用于预测输出序列。
序列自动编码器与上述概念相似,但它是一个无监督学习模型。其目标是重建输入序列本身。这意味着我们在seq2seq框架中用输入序列替换输出序列。在我们的序列自动编码器中,解码器网络和编码器网络的权重是相同的(见图1)。
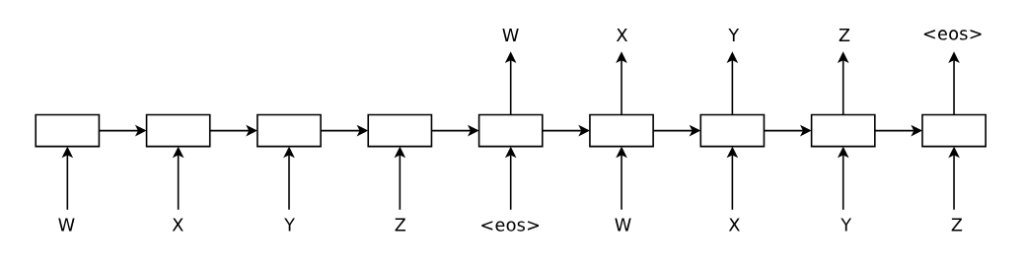
图1:用于序列“WXYZ”的序列自动编码器。序列自动编码器使用一个递归网络将输入序列读入隐藏状态,然后可用于重建原始序列。
我们发现,从序列自动编码器获得的权重可以用作另一个尝试对序列进行分类的监督网络的初始化。我们假设这是因为网络已经能够记住输入序列。这个原因,以及梯度具有捷径的事实,是我们假设序列自动编码器是初始化循环网络的一种良好且稳定方法的原因。
序列自动编码器的一个重要特性是它是无监督的,因此可以使用大量未标记的数据进行训练以提高其质量。我们的结果是,额外的未标记数据可以提高循环网络的泛化能力。这对于标记数据有限的任务特别有用。
我们还发现,循环语言模型[23]可以用作LSTM的预训练方法。这相当于删除图1中序列自动编码器的编码器部分。我们的实验结果表明,这种方法比随机初始化的LSTM效果更好。
3、方法概述
在我们的实验中,我们使用了LSTM递归网络[9],因为它们通常优于RNNs。我们的LSTM实现是标准的,并具有输入门、遗忘门和输出门[6, 7]。我们将基础LSTM与通过序列自编码器方法初始化的LSTM进行了比较。在我们的实验中,当LSTM通过序列自编码器初始化时,我们称这种方法为SA-LSTMs。当LSTM通过语言模型初始化时,我们称这种方法为LM-LSTMs。
在我们的大多数实验中,我们的输出层从最后一个时间步的LSTM输出中预测文档标签。我们还尝试了将标签置于每个时间步的方法,并从0到1线性增加预测目标的权重[24]。通过这种方式,我们可以将梯度注入到递归网络的早期步骤中。我们将这种方法称为线性标签增益。
最后,我们还尝试了将监督学习任务与序列自编码器联合训练的方法,并称这种方法为联合训练。
4、实验
在我们的LSTM实验中,我们遵循了[31]中描述的基本方法,对单元输出和梯度进行了裁剪。我们关注的基准是文本理解任务,所有数据集都是公开的。这些任务是情感分析(IMDB和烂番茄)和文本分类(20个新闻组和DBpedia)。在这些数据集上常用的方法,如词袋或n-gram,通常会忽略长距离的排序信息(例如,修饰语及其对象可能被许多不相关的词分隔开);因此,人们期望保留排序信息的循环方法能够表现出色。然而,由于优化这些网络的难度,循环模型并不是文档分类的首选方法。
在我们的序列自动编码器实验中,我们训练它在读取所有输入单词后重现整个文档。换句话说,我们没有进行任何截断或加窗。我们在每个输入序列的末尾添加一个句子结束标记,并训练网络在该标记之后开始重现序列。为了提高性能并减少GPU内存使用,我们从序列末尾开始执行最多400个时间步的截断反向传播。我们对文本进行预处理,以便将标点符号视为单独的标记,并忽略DBpedia文本中的任何非英文字符和单词。我们还删除了在每个数据集中只出现一次的单词,并且不进行任何术语加权或词干提取。
在使用批量大小为128的大约50万步训练循环语言模型或序列自动编码器后,我们使用词嵌入参数和LSTM权重来初始化监督任务的LSTM。然后,我们在该任务上进行训练,同时微调嵌入参数和权重,并在验证误差开始增加时使用提前停止。我们根据验证集选择dropout参数。
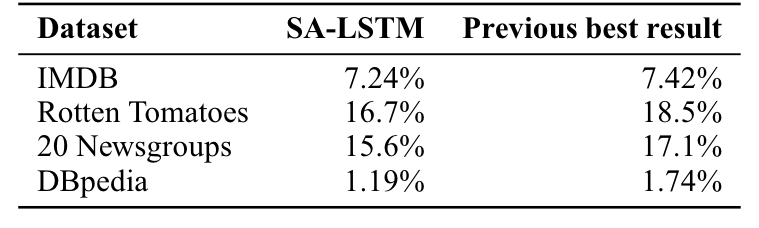
使用SA-LSTMs,我们能够匹配或超过所有数据集报告的结果。需要强调的是,以前的最佳结果来自各种不同的方法。因此,一种方法对所有数据集都取得良好结果是很重要的,大概是因为这种方法可以用作任何类似任务的一般模型。实验结果摘要如表1所示。实验的更多详细信息如下。
表1:SA-LSTMs的错误率和之前报告的最佳结果的总结。
4.1 使用IMDB数据集进行情感分析实验
在第一组实验中,我们使用了由Maas等人[21]提出的IMDB电影情感数据集作为基准来测试我们的方法。训练集中包含25,000个带标签的文档和50,000个未带标签的文档,而测试集中包含25,000个文档。我们将带标签训练文档中的15%用作验证集。每个文档的平均长度为241个单词,而文档的最大长度为2,526个单词。先前的基准方法包括词袋模型、ConvNets[12]或段落向量[18]。
由于这些文档较长,人们可能认为循环网络难以进行学习。然而,我们发现通过调整,可以训练LSTM循环网络以适应训练集。例如,如果我们将隐藏状态的大小设置为512个单元,并将反向传播截断为400步,LSTM可以表现得相当好。通过结合随机嵌入维度dropout[37]和随机单词dropout(之前未公布的技术),我们在测试集中能够达到大约86.5%的准确率,这比大多数基线方法差大约5%。
从根本上说,这种方法的主要问题在于其不稳定性:如果我们增加隐藏单元的数量或增加反向传播步骤的数量,训练会很快崩溃,即使仔细调整梯度裁剪,目标函数也会爆炸。这是因为LSTM对于长文档的超参数非常敏感。相比之下,我们发现SA-LSTM表现更好且更稳定。如果我们使用序列自动编码器,改变隐藏状态的大小或反向传播步骤的数量几乎不会影响LSTM的训练。这一点非常重要,因为这使得模型在实际训练中更加实用。
通过使用序列自动编码器,我们以一种方式克服了LSTM中的优化不稳定性,从而可以在训练集上快速且容易地实现完美的分类。为了避免过拟合,我们再次使用输入维度dropout,并在验证集上选择dropout率。我们发现,对于这个数据集来说,丢弃80%的输入嵌入维度效果很好。我们的实验结果与先前的基准方法一起显示在表2中。我们还添加了一个额外的基准,其中我们使用训练集上的word2vec嵌入来初始化LSTM。