预训练语言模型必读文献02-context2vec: Learning Generic Context Embedding with Bidirectional LSTM
摘要
上下文表示对于各种自然语言处理(NLP)任务至关重要,如词义消歧、命名实体识别、指代消解等等。在这项工作中,我们提出了一种神经模型,该模型使用双向长短期记忆网络(LSTM)从大型语料库中高效地学习通用的上下文嵌入函数。通过非常简单地应用我们的上下文表示,我们成功超越或接近达到句子补全、词汇替换和词义消歧任务的最新结果,同时大大优于流行的平均词嵌入上下文表示。我们公开了我们的代码和预训练模型,这表明它们可以在各种自然语言处理任务中发挥重要作用。
引言
通用词嵌入以紧凑的低维表示形式捕获单个词汇的语义和句法信息。虽然它们被训练以优化一个通用的、与任务无关的目标函数,但人们发现词嵌入在广泛的自然语言处理(NLP)任务中都很有用,近年来产生了巨大的整体影响。
这一领域的一个重大进展是引入了高效的模型,如word2vec(Mikolov等,2013a)和GloVe(Pennington等,2014),用于从非常大的语料库中学习通用词嵌入。从这些语料库中捕获信息大大提高了词嵌入对于无监督和半监督NLP任务的价值。
为了对具体的目标词实例进行推断,良好的目标词类型和给定上下文的表示都是有帮助的。例如,在句子“I can’t find [April]”中,我们需要同时考虑目标词April及其上下文“I can’t find [ ]”,以推断April可能指的是一个人。这一原则适用于各种任务,包括词义消歧、指代消解和命名实体识别(NER)。
与目标词一样,上下文也通常通过词嵌入来表示。在无监督环境中,这些表示被发现对于测量上下文敏感的相似性(Huang等,2012)、词义消歧(Chen等,2014)、词义归纳(Kagebäck等,2015)、词汇替换(Melamud等,2015b)、句子补全(Liu等,2015)等任务都很有用。在此类任务中使用的上下文表示通常只是目标词周围窗口内相邻词汇的单独嵌入的简单集合,或者是这些嵌入的(有时是加权的)平均值。我们注意到,这些方法没有包括任何优化整个句子上下文表示作为一个整体的机制。
在有监督设置中,各种自然语言处理系统使用标记数据来学习如何以更优化的、特定于任务的方式考虑上下文词汇表示。这在诸如分块、命名实体识别、语义角色标注和指代消解等任务中得到了应用(Turian等,2010;Collobert等,2011;Melamud等,2016),主要是通过考虑目标词周围窗口中的词汇嵌入来实现的。最近,双向循环神经网络,特别是双向长短期记忆网络(LSTM),被用于此类任务,以学习更广泛的句子上下文的内部表示(Zhou和Xu,2015;Lample等,2016)。由于有监督数据的大小通常有限,因此已经证明,使用在大语料库上预先训练的词嵌入来训练这样的系统可以显著提高性能。然而,预训练的词嵌入对于目标词与其整个句子上下文之间的相互依赖关系所携带的信息有限。为了建立这种(以及更多的)模型,有监督的系统仍然需要严重依赖其有限的监督数据。
在这项工作中,我们提出了context2vec,这是一个无监督的模型和工具包,用于使用双向LSTM有效地学习广泛的句子上下文的通用上下文嵌入。本质上,我们使用大量的纯文本语料库来学习一个神经网络模型,该模型将整个句子上下文和目标词嵌入到相同的低维空间中,该空间进行了优化以反映目标与其整个句子上下文之间的相互依赖关系。为了证明它们的高质量,我们展示了通过非常简单地应用我们的上下文表示,我们能够在句子补全、词汇替换和词义消歧任务上达到或接近最先进的结果,同时大大优于常见的词嵌入平均值表示(表示为AWE)。我们进一步假设,无监督和半监督系统都可能从使用我们的预训练模型中受益,而不是或除了单独的预训练词嵌入之外。
Context2vec的神经网络模型
模型概述
我们模型的主要目标是学习一个通用的、与任务无关的嵌入函数,用于目标词周围的变长句子上下文。为此,我们提出了一种神经网络架构,该架构基于word2vec的CBOW架构(Mikolov等,2013a),但它用双向LSTM的更强大的神经网络模型,取代了固定窗口内词嵌入平均值的简单上下文建模。
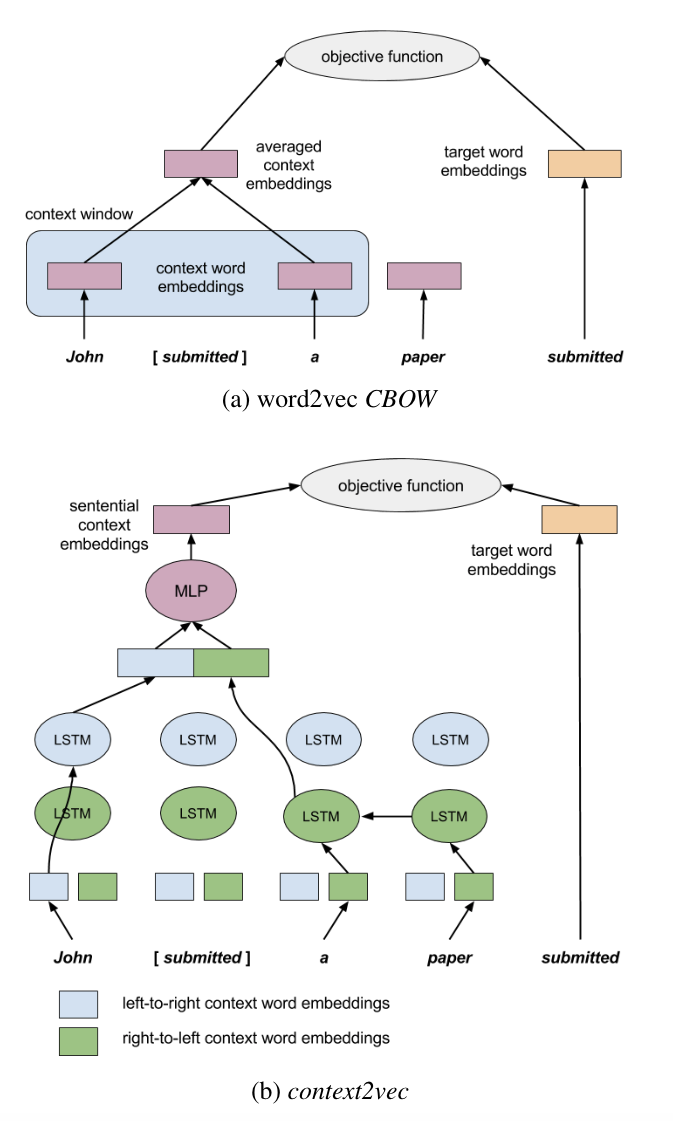
图1:word2vec和context2vec架构图
我们提出的架构如图1所示,同时展示了类似的word2vec架构。两个模型都通过将上下文和目标词嵌入到相同的低维空间中,同时学习上下文和目标词的表示,目的是通过逻辑线性模型让上下文预测目标词。然而,我们利用了一个更强大的参数模型来捕捉句子上下文的本质。
图1b的左侧展示了context2vec如何表示句子上下文。我们使用双向LSTM循环神经网络,一个LSTM网络从左到右输入句子中的词,另一个从右到左输入。这两个网络的参数是完全独立的,包括两组独立的从左到右和从右到左的上下文词嵌入。为了在句子中表示目标词的上下文(例如,“John [submitted] a paper”),我们首先将表示其从左到右上下文(“John”)的LSTM输出向量与表示其从右到左上下文(“a paper”)的向量进行连接。通过这样,我们旨在捕捉句子上下文中的相关信息,即使它远离目标词。接下来,我们将这个连接后的向量输入到一个多层感知机中,以能够表示上下文两侧之间的非平凡依赖关系。我们将这一层的输出视为目标词周围整个联合句子上下文的嵌入。同时,目标词本身(图1b右侧)用其自身的嵌入来表示,其维度与句子上下文的维度相同。我们注意到,我们的模型和word2vec的CBOW(图1a)之间的唯一(但至关重要的)区别是,CBOW将目标词周围的上下文表示为其周围窗口中的上下文词嵌入的简单平均值,而context2vec则利用整个句子的神经表示来表示上下文。
最后,为了学习我们网络的参数,我们使用了word2vec的负采样目标函数,其中正对是目标词及其整个句子上下文,而相应的k个负对是作为随机目标词从词汇表的(平滑)一元分布中采样,并与相同的上下文配对。通过这种方式,我们同时学习了上下文嵌入网络参数和目标词嵌入。
与word2vec和类似的词嵌入模型相比,这些模型主要使用上下文建模,并将目标词嵌入视为其主要输出,而我们的主要关注点是上下文表示。我们的模型通过为句子上下文和它们关联的目标词分配相似的嵌入来实现其目标。此外,与word2vec模型中的情况类似,这间接导致为与相似句子上下文关联的目标词分配相似的嵌入,反之亦然。在以下几节中,我们将展示这些属性如何使我们的模型变得有用。
形式化规范与分析
我们使用双向长短期记忆(LSTM)递归神经网络来获取句子级别的上下文表示。设lLS为从左到右读取给定句子中单词的LSTM,而rLS为从右到左读取单词的反向LSTM。给定一个句子$ w_{1:n} $ w1:n,我们为目标词wi定义的“浅层”双向LSTM上下文表示是以下向量的连接: